Learning to Know Where to See: A Visibility-Aware Approach for Occluded Person Re-identification
Jul 1, 2021·,,,,, ,·
0 min read
,·
0 min read
Jinrui Yang
Jiawei Zhang
Fufu Yu
Xinyang Zhang
Mengdan Zhang
Xin Sun
Ying-Cong Chen
Wei-Shi Zheng
Abstract
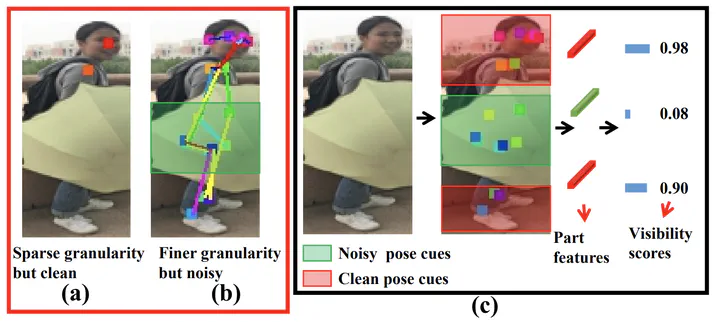
Person re-identification (ReID) has gained an impressiveprogress in recent years. However, the occlusion is still acommon and challenging problem for recent ReID methods.Several mainstream methods utilize extra cues (e.g., humanpose information) to distinguish human parts from obstacles to alleviate the occlusion problem. Although achievinginspiring progress, these methods severely rely on the fine-grained extra cues, and are sensitive to the estimation errorin the extra cues. In this paper, we show that existing methods may degrade if the extra information is sparse or noisy.Thus we propose a simple yet effective method that is robustto sparse and noisy pose information. This is achieved bydiscretizing pose information to the visibility label of bodyparts, so as to suppress the influence of occluded regions.We show in our experiments that leveraging pose informa-tion in this way is more effective and robust. Besides, ourmethod can be embedded into most person ReID modelseasily. Extensive experiments show that our method outperforms the state-of-the-art. We will release the source codesafter the paper is accepted.
Type
Publication
In Proceedings of the IEEE International Conference on Computer Vision